CO5BOLD has been also compiled and tested on up to 22 processors on the machines of the UK Astrophysical Fluids Facility (UKAFF) in Leicester, England. UKAFF operates two machines: an SGI Origin 3800 with 128 processors (named ``ukaff''), and an older SGI Origin 2000 with 22 processors (named ``grand'') which is mainly used for development and test purposes. Both machines are binary compatible. At the time of testing (April 2003) the SGI MIPSpro Compilers (Version 7.4) was installed.
Most of the compiler switches given in the previous section were used, except for the following modifications which either gave empirically a better performance or were recommended by the UKAFF Hints for users:
-Ofast: Replaces -O3, gave better performance
-LNO:cs1=32k:ls1=32:cs2=8M:ls2=128: Explicit cache
architecture added
-Ofast is now the default selected by the
configure script for all SGIs with IP35 architecture.
The cache architecture settings are activated for the UKAFF machines
only.
A glitch in the system libraries made it necessary to add a
work-around to the source code (file rhd.F90). A ``bus error''
occurred whenever the system routine ``flush'' was trying to flush an
empty file buffer. The temporary work-around was simply to add a write statement
before every call of ``flush''. This made the log-file look less nice
but did the job. Now, the few ``flush'' statements that are not necessarily
preceded by a write statement are removed.
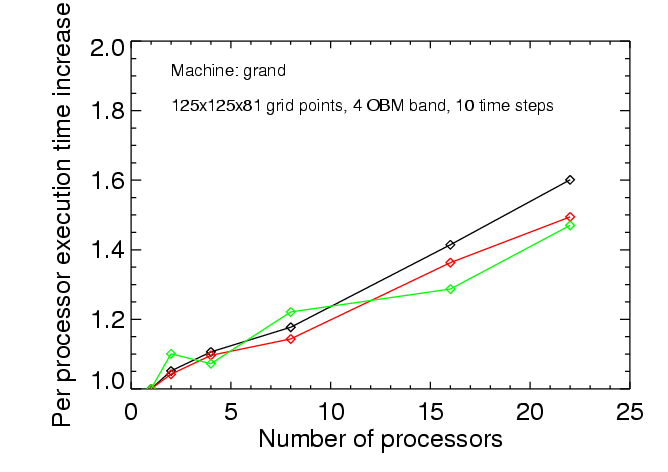
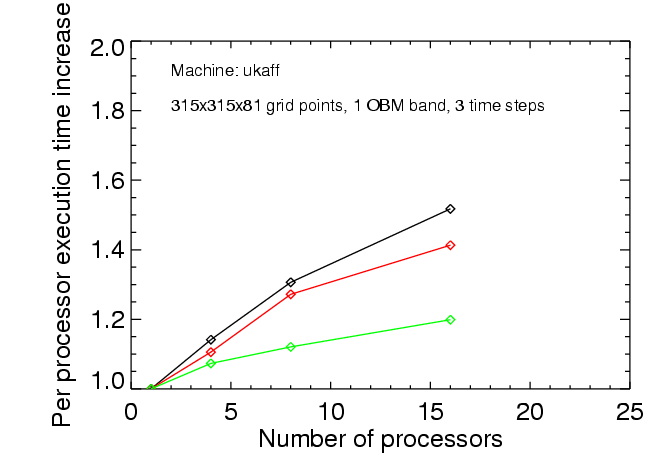
The main goal was to investigate the scaling of the performance of CO5BOLD with the number of processors. This was done only for the MSrad module, considering local surface convection models. Two model sizes were tested: a small one with 125x125x81 grid points employing non-grey radiative transfer (4 frequency bands), and a large one with 315x315x81 grid points employing grey radiative transfer. Rather short runs of 10 (small model) and 3 (large model) time steps were performed. Even for the large model the memory demand was ca. 800Mb, which is very modest considering that every sub-node of the machine -- consisting of 4 processors -- has 2Gb of memory.
The results are summarized in the following three figures. The black lines give the scaling of the total time, the green lines the scaling of the time needed by the hydrodynamics routines, and the red lines the scaling of the radiative transfer routines. The scaling is presented as the increase of processing time per processors as the problem is distributed among more and more processors. The times are normalized to the time that is used in a scalar, i.e. single processor setup. Ideally, one would like a constant behavior which stays close to one.
The perhaps most interesting result is that the speedup on ``ukaff'' is about 11 for the large model on 16 processors. Perhaps not ideal, but within the range of practical interest. In general, the hydrodynamics routines scale more favorably than the radiation routines. This is perhaps simply related to the fact that in explicit hydrodynamics communication is restricted to neighboring grid cells.
For those wondering: the black curves do not lie between the red and green curve since more components than just radiation and hydrodynamics add up to the total time. Furthermore, the normalization of the execution times given by CO5BOLD is not exact.